Team Description
- PI: Katsuki Fujisawa (Kyushu University)
- co-PI: Toyotaro Suzumura (Barcelona Supercomputer Center), Hitoshi Sato (National Institute of Advanced Industrial Science and Technology)
- Research Period: 2011 – 2016
- Research highlights in pdf
Published Software
- SDPARA High-Performance General Solver for Extremely Large-scale Semidefinite Programming Problems
- ScaleGraph A Billion-Scale Graph Processing Library
- HAMAR : Highly Accelerated Map Reduce
Project Overview
The objective of this project is to develop advanced computing and optimization infrastructures for extremely large-scale graphs on post peta-scale supercomputers. The large-scale graph analysis has attracted significant attention as a new application of the next-generation super computer. However, it is extremely difficult to realize a high-speed graph processing in various application fields by utilizing previous methods. The objective of our project is to develop advanced computing and optimization infrastructures for extremely large-scale graphs on the next-generation supercomputers. We also commenced another research project for creating new industrial applications in combination with many companies

Large-scale Graph Analysis and Graph500 Benchmarks
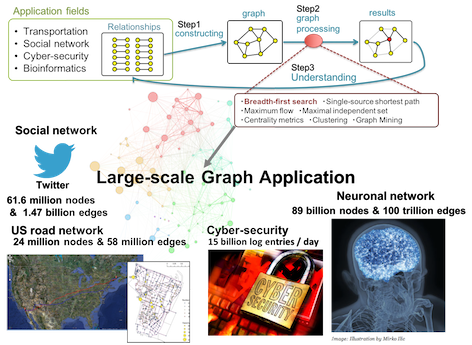
In recent year, the demands for high-speed graph processing has been remarkably increasing after converting the real-world data into the graph data. The graph processing cycle starts from the target relation and the generation of a graph. Next, we analyze and process it by utilizing graph algorithms. We can finally understand the relationship and characteristic of the target. The graph consists of the node and edge sets. For example, a node corresponds to an intersection in a road network and an edge corresponds to a road between two intersections. In the analysis of social networks such as Twitter, a node corresponds to a user and an edge corresponds to the Twitter follower relationship between two users. Besides, we usually handle even larger-scale graph data in the cyber security and neural network.
In this project, we have advanced the development of the software package that performs high-speed processing of large-scale graphs on the next generation supercomputer since 2011. We combined highly advanced software technologies
- Algorithms to reduce redundant graph searches
- Optimization of communication performance on massively parallel computers connected by thousands to tens of thousands of high-speed networks
- Optimization of memory access on multicore processors. We finally succeeded in coping with large-scale and complicated real data expected in the future and developing graph search software with the world’s highest performance. As a result,
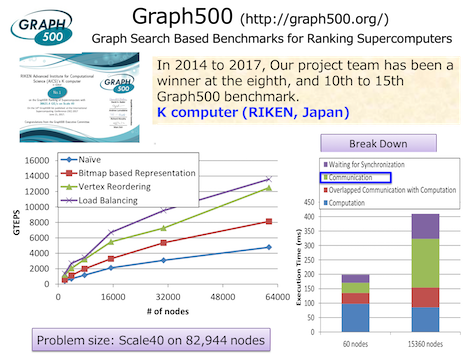
We have won the world first place for six consecutive periods (a total of seven periods from 2014 to 2017) at the Graph 500 benchmark that has been done since 2010 with the result of using K computer.
Cyber-physical System and Industrial Applications of Large-Scale Graph Analysis and Optimization Problem
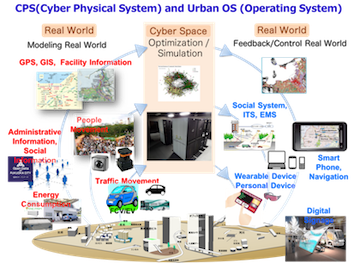
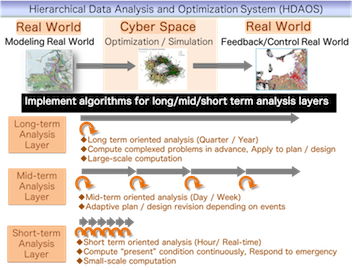
We commenced our research project for developing the Urban Operating system (OS) for a large-scale city, in 2013. The Urban OS, which is regarded as one of the emerging applications of the cyber-physical system (CPS), gathers big data sets of people and transportation movements by utilizing different sensor technologies and storing them in the cloud storage system. Here, we focus on the Hierarchical Data Analysis and Optimization System (HDAOS) based on CPS. First, we gather a variety of data sets on a physical space and generate mathematical models for analyzing the social mobility of real worlds. In the next step, we apply optimization and simulation techniques to solve them and check the validity of solutions obtained on the cyber space. We finally feed these solutions into the real world. HDAOS shows three analysis layers, and we can choose the appropriate one according to a given time for the decision-making process. We classify many optimization algorithms into three layers according to both the computation time needed to solve problems, and the data size of the optimization problem. We have developed parallel software packages for many optimization problems categorized into these three algorithmic layers. In the cyber physical system, it is possible to create new industries by optimizing and simulating the real-world data in social mobility.
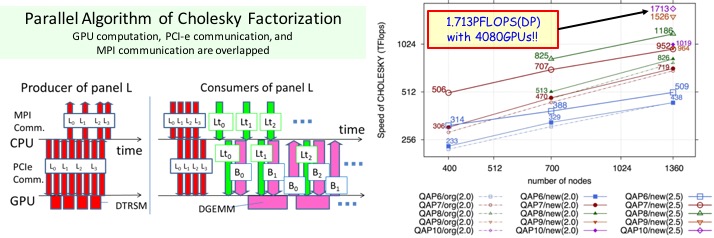
High-Performance General Solver for Extremely Large-scale Semidefinite Programming Problems
In the last decade, mathematical optimization programming problems have been intensively studied in both their theoretical and practical aspect in a wide range of fields, such as combinatorial optimization, struc- tural optimization, control theory, economics, quantum chemistry, sensor network location, data mining, and machine learning. The semidefinite programming (SDP) problem is a predominant problem in mathematical optimization.
SDPARA is a parallel implementation of the interior-point method for SDP Parallel computation for two major bottlenecks
- ELEMENTS : Computation of Schur complement matrix (SCM)
- CHOLESKY : CCholesky factorization of Schur complement matrix (SCM)
SDPARA could attain high scalability using 16,320 CPU cores on the TSUBAME 2.5 supercomputer and some techniques of processor affinity and memory interleaving when the computation of SCM (ELEMENTS) constituted a bottleneck. With 4,080 NVIDIA GPUs on the TSUBAME 2.0 & 2.5 supercomputer, our implementation achieved 1.019 PFlops(TSUBAME 2.0) & 1.713 1.774PFlops(TSUBAME 2.5) in double precision for a large-scale problem (CHOLESKY) with over two million constraints.
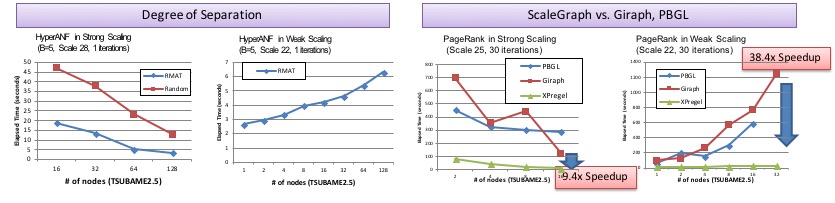
ScaleGraph: A Billion-Scale Graph Processing Library
An open source highly scalable large scale graph analytics library beyond the scale of billions of vertices and edges on distributed and parallel systems. The library is available at http://www.scalegraph.org/
- Currently Supported Graph Algorithms
- PageRank, Bread First Search, Spectral Clustering, Degree Distribution
- Betweenness Centrality, Degree of Separation (HyperANF), Strongly Connected Component
- Maximum Flow, Single Source Shortest Path, Community Detection, Information Diffusion
- Library Architecture Overview
- Pregel-based Bulk Synchronous Parallel Graph processing framework (Xpregel)
- Built on top of our extended and optimized X10 (parallel distributed programming language )
- Full support for native MPI collective communication
- Native support for hybrid (MPI and multi-threading) parallelism
- Performance Evaluation
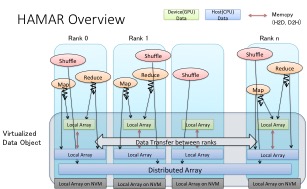
HAMAR Highly Accelerated Map Reduce
A Data Parallel Processing Framework for Large-scale Supercomputers w/ GPUs and NVM devices
- Object-oriented
- Weak-scaling over 1000 GPUs
- Out-of-core GPU memory management
- Optimized data formats
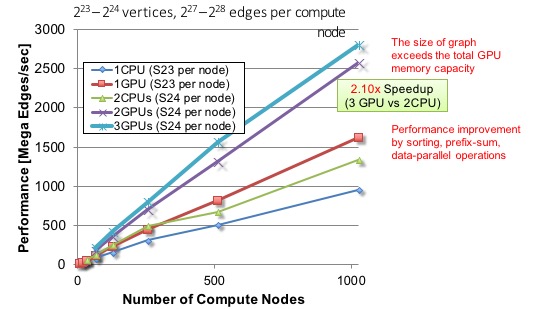
Weak Scaling on K20X-based TSUBAME2.5 MapReduce-based Page Rank Application for RMAT Graph (Graph500)