Team Description
- PI: Masaaki Kondo (University of Tokyo)
- co-PI: Ikuo Miyoshi (Fujitsu Ltd.), Koji Inoue (Kyushu University), Shinobu Miwa (UEC Tokyo)
- Research Period: 2012 – 2017
- Research highlights in pdf
Published Software
- Power-Aware Resource Manager (based on SLURM Workload Manager)
- Objective: Providing a common resource management tool for power-constrained HPC systems.
- Functionality: Job scheduling and power-knob control for maximizing system throughput within a power budget.
Overview
Power consumption is now becoming a first class design constraint for developing future post-petascale computing systems. To achieve exa-flops level performance with realistic power provisioning of 20-30 megawatts, significant power efficiency improvement over today’s supercomputers is necessary. In order to maximize effective performance within a power constraint, we need a paradigm shift from the worst-case design strategy to the power-constraint adaptive system design (P-CAS), which allows the system’s peak power to exceed maximum power provisioning with adaptively controlling power-knows equipped in hardware components so that effective power consumption at runtime is under the power constraint as shown in Fig 1. This concept is recently known as hardware overprovisioning.
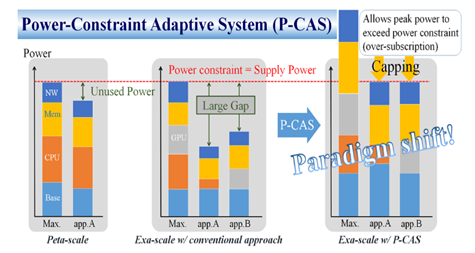
To realize post-petascale systems with the P-CAS concept, we have been conducting research and development on a software framework for code optimization and system power management which adaptively control power performance knobs under a given power constraint. There are several key challenges to be addressed: 1) power-aware job scheduling to maximize system throughput while minimizing underutilized power resources, 2) framework to maximize application performance under a given power constraint, and 3) power performance simulation and analysis framework for exascale applications.
Power Aware Recource Manager
In overprovisioned systems, power budget allocated for each node should be controlled by power-knobs such as dynamic voltage and frequency scaling (DVFS) or a power capping mechanisms. One of the key challenges is to develop a runtime system for optimizing and controlling power budget for each job as well as job scheduling according to available power budget of the entire system so that the total system throughput is maximized.
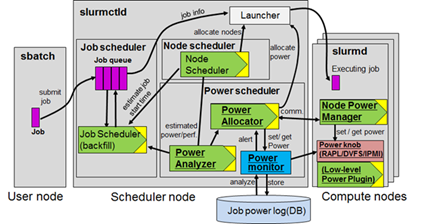
In order to provide a common resource management tool for hardware-overprovisioned HPC systems, we are developing a power-aware resource management framework based on SLURM workload manager. Our framework provides flexible plugin interfaces and APIs for power management that can be easily extended to implement site-specific strategies. We deployed this framework on the 965-node supercomputer system at Kyushu University to evaluate the power-performance characteristics of hardware over- provisioning on a large scale HPC system [1]. Our results indicate that it is indeed possible to safely overprovision hardware in production (Fig.3 left). We also find that the degree of overprovisioning affects system throughput differently depending on the characteristics of job mix (Fig.3 right).
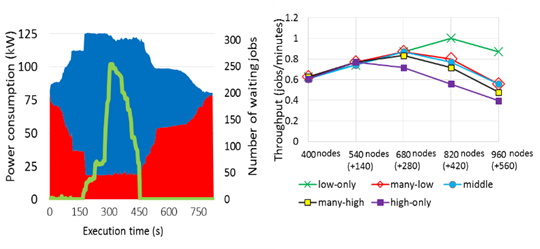
Since effective power consumption differs application by application or phase by phase in an application, we have developed an adaptive power scheduling algorithm [2].
Power-Performance Optimization Framework
While there are strong demands for maximizing application performance under a given power budget, optimizing power-know control by application programmer is a burdensome task since it is complex process involving the collection/analysis of statistics from both hardware and software and power resource allocation to several hardware components with available power-knob. To help develop optimized codes in power-constrained HPC systems, we have designed and implemented a versatile power management framework which tries to automatically analyze the program code, insert power-know control primitives, and optimize power allocation (Fig. 4).
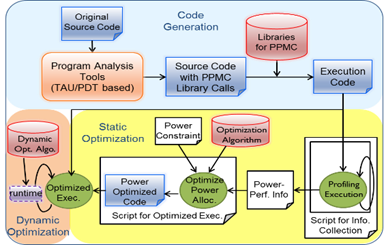
As a use case, this framework can be utilized for improving application performance under power variations among computing nodes. Modern high performance processors suffer from increasingly large power variations owing to the chip manufacturing process. These variations lead to power inhomogeneity in current systems and manifest into performance inhomogeneity with power capped executions resulting in poor system performance.
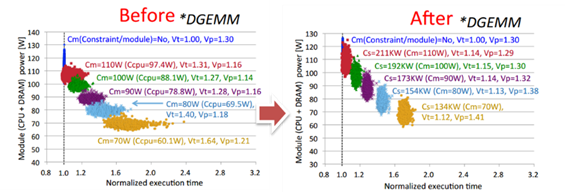
To tackle this issue, we have developed a variation-aware power budgeting scheme to maximize effective application performance. The scheme can effectively mitigate variation as shown in Fig. 5 and experimental results using a 1,920 socket system show up to 5.4X speedup, with an average speedup of 1.8X across evaluated benchmarks, compared to a variation-unaware power allocation scheme [3].
Power-Performance Simulation Framework
Optimizing power-efficiency of an application relies on the knowledge about its runtime characteristics. In large scale applications, obtaining such characteristics by profiling is not easy since there is only a limited chance of using large number of nodes. It is necessary to provide a low-cost and highly flexible simulation environment by which users can obtain power-performance behavior of their applications without actually execute them.
In this project, we have co-developed an interconnect power-performance simulator TraceRP with Lawrence Livermore National Laboratory. This simulator is implemented based on trace replay and network simulation framework TraceR and can estimate power consumption of an interconnection network with an on/off link scheme.